Architecture
CITYdata is a middleware that enables researchers and data analysts to perform complex operations on urban data from heterogeneous sources. CITYdata is developed by a team of researchers and professionals at the Ptidej Team and Next-Generation Cities Institute (NGCI) at Concordia University, Montréal, Canada.
In this document, we provide a comprehensive overview of CITYdata’s features, requirements, and architectural design. This document is structured following the arc42 template by Gernot Starke and Peter Hruschka, a well-established standard for documenting software architecture.
1. Introduction & Goals
1.1 Requirements Overview
CITYdata is designed to facilitate seamless data operations by abstracting the complexity of working with heterogeneous data sources. The system enables users to perform sophisticated data fetching and transformation workflows through the use of the following core abstractions:
Producer: connects to data sources and fetches data.
Operation: describes transformations to be performed on producer outputs (data).
Runner: calls a series of producers, executes a series of operations on the producer’s outputs, and then outputs the resulting data.
Within TOOLS4CITIES, CITYdata primarily handles urban data such as building energy consumption. However, its flexible design makes it applicable across different domains and data types.
1.2 Quality Goals
The following represent the primary quality goals that drive CITYdata’s architectural decisions and design principles:
Goal |
Description |
Usability |
Provide easy access to data for researchers and analysts with a minimal learning curve. |
Functionality |
Enable flexible custom pipelines for data fetching, transformation, and analysis. |
Extensibility |
Allow extension via custom Producers, Operations, and Runners. |
In section 4 (Solution Strategy), we explain the architectural strategies and design patterns we employ to attain these goals.
1.3 Stakeholders
The following people and organizations have significant influence in shaping CITYdata’s architectural decisions and technical direction:
Stakeholder |
Description |
Ptidej Team + NGCI |
Research groups responsible for designing and developing TOOLS4CITIES, which are also the main users of CITYdata. |
Research Partners |
Collaborators who validate, enhance, and promote TOOLS4CITIES. |
2. Architectural Constraints
The following are external factors and limitations that constrain our freedom in making design and implementation decisions for CITYdata:
Constraint |
Description |
Available Data |
The data richness provided by CITYdata depends on the diversity and availability of data sources and formats it can process. Coverage expands incrementally over time. |
User Queries |
Users communicate with CITYdata via queries that only support a limited number of commands. The query syntax may need to be improved over time to make more expressive and powerful. |
User Interfaces |
CITYdata currently has no Graphical UI, meaning users can only interact with it by writing HTTP requests in a programming language or using tools such as Postman. |
3. Context & Scope
3.1 End-user Context
Urban datasets comes in many forms. Every municipality and organization represents buildings and related data, such as energy consumption and space occupancy, using different formats, standards, and file structures. CITYdata enables users to retrieve urban datasets from a catalog and apply transformations like aggregation, filtering, and merging without having to implement these operations themselves.
Users interact with CITYdata by sending HTTP requests to its REST API. On every request payload, users will send a JSON query that describes which dataset they want to work with and which operations they want to apply to this dataset. For example, to obtain energy consumption data, write:
"use": "ca.concordia.encs.citydata.producers.EnergyConsumptionProducer"
To pass parameters to the Producer, write:
"withParams": [
{
"name": "city",
"value": "montreal"
},
{
"name": "startDatetime",
"value": "2021-09-01 00:00:00"
},
{
"name": "endDatetime",
"value": "2021-09-01 23:59:00"
},
{
"name": "clientId",
"value": 1
}
]
To apply and parametrize operations, write:
"apply": [
{
"name": "ca.concordia.encs.citydata.operations.JsonArrayAverageOperation",
"withParams": [
{
"name": "keyName",
"value": "consumptionKwh"
},
{
"name": "roundingMethod",
"value": "none"
}
]
}
]
The complete query is a valid JSON, and looks like this:
{
"use": "ca.concordia.encs.citydata.producers.EnergyConsumptionProducer",
"withParams": [
{
"name": "city",
"value": "montreal"
},
{
"name": "startDatetime",
"value": "2021-09-01 00:00:00"
},
{
"name": "endDatetime",
"value": "2021-09-01 23:59:00"
},
{
"name": "clientId",
"value": 1
}
],
"apply": [
{
"name": "ca.concordia.encs.citydata.operations.JsonArrayAverageOperation",
"withParams": [
{
"name": "keyName",
"value": "consumptionKwh"
},
{
"name": "roundingMethod",
"value": "none"
}
]
}
]
}
Finally, users will send the JSON query payload to the URLs POST /apply/sync (for synchronous processing) or POST /apply/async (for asynchronous processing).
3.2 Technical Context
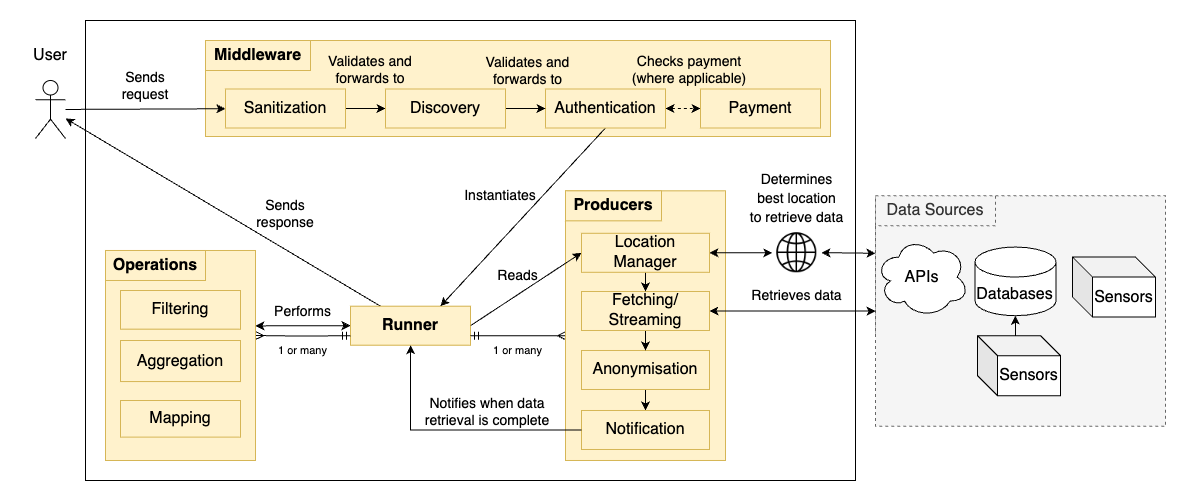
CITYdata’s architecture processes user HTTP requests and manages data operations through four main subsystems: Middleware, Runners, Producers, and Operations. CITYdata follows a layered processing approach where the Middleware serves as the entry point, receiving and processing user requests before spawning appropriate instances of Runners, Producers, and Operations to handle the actual data operations.
The typical request undergoes four initial steps in the Middleware subsystem:
Sanitization: This subsystem receives, validates, and processes the input parameters of incoming requests to remove invalid, malformed, or potentially malicious inputs. If validation fails, CITYdata responds with a detailed error message to guide the user in correcting their request. This step protects CITYdata from injection attacks and prevents downstream components from processing invalid data.
Discovery: This subsystem publicly lists and catalogs all available Producers and Operations currently deployed within CITYdata, along with their capabilities and required input parameters. Users can query this discovery service to explore available data sources and transformations, allowing them to understand which combinations of Producers and Operations they can request to build their desired data pipeline.
Authentication: This subsystem manages comprehensive access control and permission management, supporting multiple authentication protocols and cryptographic security methods. It enables secure authentication across multiple scenarios: between end users and CITYdata, between CITYdata and upstream data providers, and between CITYdata and IoT devices that may serve as data sources. This multi-level authentication ensures that data access is restricted according to organizational policies and regulatory requirements.
Payment: For datasets or APIs that require financial transactions, this subsystem facilitates connections with external payment gateway services. It handles billing logic, subscription management, and payment processing necessary to access premium or proprietary datasets while maintaining a clear separation between CITYdata and payment service providers.
Next, a Runner is spawned and then a Producer implement the following processes:
Location Manager: This subsystem determines the geographic location and availability of the requested data source across globally distributed database instances and edge servers. It employs intelligent selection algorithms to route requests to the optimal server based on factors including current availability, network proximity, response time, and load balancing. This optimization improves user experience by reducing latency and increasing reliability.
Fetching/Streaming: This subsystem manages multiple abstractions and patterns related to data retrieval from diverse sources. It handles creation and management of database transactions, implements batch and streaming data retrieval modes to accommodate different use cases and data sizes, manages subscriptions to IoT message brokers such as MQTT, and provides resilience mechanisms for recovery in case of network failures or connection loss. This layer abstracts away the complexity of different data source protocols.
Anonymisation: Recognizing privacy as a critical concern, this process removes or obfuscates sensitive portions of retrieved data that cannot be exposed to the requesting user due to privacy regulations, ethical guidelines, or organizational policy. Producers apply parameterized anonymisation rules that are customized based on the permissions and privileges assigned to each user. These anonymisation rules may be either statically hardcoded into the AbstractProducer base class for simplicity or implemented as parametrizable Operations for greater flexibility.
Notification: This subsystem notifies relevant Runners when requested data is ready for processing through the well-established Observer design pattern. This asynchronous notification mechanism decouples data production from consumption and allows CITYdata to handle long-running data retrieval operations gracefully.
Finally, the Runner transforms the data based on the Operation list given by the user. For a more visual overview of subsystems, please see Section 5 (Building Block View).
4. Solution Strategy
We implement the following strategic approaches and design patterns to meet the quality goals outlined in Section 1.2:
Goal |
Description |
Usability |
REST API and query language abstracts complexity for non-experts. |
Functionality |
Dynamic composition of Producers and Operations enable flexible pipelines. |
Extensibility |
Interfaces and classes allow for inheriting and extending Producers, Operations, and Runners. |
5. Building Block View
This diagram illustrates the major components and subsystems that compose CITYdata, showing their relationships and primary responsibilities.
6. Runtime View
(TBD)
7. Deployment View
CITYdata is currently a single-node application running in an NGCI server. User requests pass through an NGINX reverse proxy before reaching CITYdata on a different server.

8. Crosscutting Concepts
(TBD)
9. Architectural Decisions
(TBD)
10. Quality Requirements
(TBD)
11. Risks & Technical Debt
(TBD)
12. Glossary
Term |
Definition |
API |
Application Programming Interface |
HTTP |
Hyper Text Transfer Protocol |
IoT |
Internet of Things |
JSON |
JavaScript Object Notation |
MQTT |
Message Queuing Telemetry Transport |
REST |
Representational State Transfer |